První série třicátého druhého ročníku KSP
Celý leták v PDF.
Právě si prohlížíte komentáře k úlohám první série KSP-H (přesněji k těm, ke kterým jsme uznali, že se komentář hodí). Připomínáme, že od loňska jsou řešení každé série rozdělena na dvě části: na samotná autorská řešení, která vydáváme brzy po termínu série, a komentáře k došlým řešením, která vydáváme až po opravení vašich řešení.
Pokud se vám cokoliv nezdá nebo máte nějaký dotaz, neváhejte se ozvat na našem fóru nebo emailem na známou adresu.
Komentáře k úlohám
 32-1-2 Stavba rampy (Zadání) (Řešení)
32-1-2 Stavba rampy (Zadání) (Řešení)
V zadání chybělo, že výšky musejí být různé. Za to se omlouváme. Kdo zkoušel řešit úlohu bez tohoto omezení, mohl zjistit, že je to podstatný rozdíl.
Mnoho řešitelů předpokládalo, že výšky začínají jedničkou a rostou o 1. Toto je drobné zjednodušení, ale řešení se dá přímo upravit.
Častým přístupem bylo dívat se na cykly a třídit každý samostatně. Tento přístup nefunguje, toto uvidíme například na tomto vstupu:
10 4000 1000 2000 3000
Třídění cyklu samostaně stojí nejméně 1000 ×3 + 2000 + 3000 + 4000 = 12 000. S použitím desítky vypadá seřazování následovně:

Ještě se objevila „hladová“ řešení optimalizující postupně různými přístupy po krocích, toto vůbec nemusí vést ke globálnímu optimu. Speciálně v optimálním řešení se někdy pohybuje s krabicemi, které stojí na výsledném místě.
32-1-3 Čokoládová tyčka (Zadání) (Řešení)
Většina došlých řešení postupovala stejně jako vzorové řešení. Našly se ale i tři případy s jednoduchými lineárními algoritmy, které se rozhodovaly pouze podle dvou dílků na každém konci tyčinky a bohužel nefungovaly. Zajímavé je, že na každý algoritmus bylo potřeba vymyslet jiný protipříklad. Je to zajímavé cvičení: zkuste si vymyslet nějaký podobný algoritmus a dokázat, že nefunguje.
Objevila se však i řešení, která používala rekurzi. Můžeme procházet stavový prostor hry stejně jako algoritmus minimax, který se používá k nalezení nejvýhodnějšího tahu ve hře dvou hráčů. Principem je, že ve vašem tahu vybíráte maximum, tedy možnost s nejlepším skóre ze všech možných tahů, zatímco v tahu protihráče vybíráte minimum, tedy nejhorší skóre pro vás, ale nejlepší pro soupeře. Po dvou tazích jste zase na řadě vy a řešíte úplně stejný problém znovu, jen s tyčinkou o dva dílky menší. Výsledný rekurzivní vzoreček tedy bude vypadat takto:
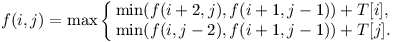
Vybíráte ten lepší ze dvou možných tahů: Buď si ukousnete dílek T[i] a zbyde na vás po tahu soupeře ta horší ze dvou možností, nebo si ukousnete dílek T[j] z druhé strany a opět čekáte, co vám soupeř nechá. Funkce f(i, j) tedy počítá maximální zisk prvního hráče na úseku tyčinky [i,j] a celkový výsledek zjistíme zavoláním f(0, D-1).
Ještě musím upozornit, že je potřeba si při volání rekurzivní funkce zapisovat již spočítané mezivýsledky do dvojrozměrného pole, jinak byste počítali hodnoty pro všechny úseky zbytečně vícekrát a časová složitost by rostla exponenciálně.
32-1-6 Data na OSMou (Zadání) (Řešení)
Došlo nám mnoho pěkných řešení a mnoho pěkných heatmap, děkujeme za ně. Většinu jsme vám napsali přímo do hodnocení vašich řešení, ale některé věci chceme zdůraznit všeobecně.
První z nich je obecný princip práce s daty – pokud očekáváte, že vaše data budou používány v dalších skriptech a není to už finální výstup pro uživatele, tak je dobré zvolit takový formát uložení dat, který je rozumně strojově zpracovatelný. Takový seznam identifikátorů mnoha stovek až tisíců pítek je přesně věc, která není finálním výstupem pro uživatele, ale je to něco, co chcete načítat například něčím, co pítka vykreslí do mapy.
Rozumný výstupní formát v takovém případě je například textový soubor s jedním identifikátorem na řádek, nevhodným formátem je naopak tento seznam uložit do PDFka nebo do wordovského dokumentu. Představte si, že byste pak takový seznam měli ve vašem programu opět parsovat – v porovnání s textovým souborem je to řádově náročnější.
Naší druhou poznámkou pak je to, že část z vás zkusila k řešení seriálu použít různé externí nástroje. Dobrým externím nástrojem je například http://www.overpass-turbo.eu, což je nástroj na efektivní pokládání specifických dotazů do databáze OSM.
Někteří z vás se rozhodli některé z úloh vyřešit dotazy do tohoto nástroje a veškeré počítání jste tak nechali na externím serveru. Trochu jsme o tomto přístupu debatovali a nakonec jsme došli k tomu, že hlavním záměrem seriálu bylo ukázat vám principy zpracováních velkých dat tak, abyste si sami zkusili některé z těchto principů naprogramovat. Použití například již zmíněného http://www.overpass-turbo.eu však tyto principy nesplňuje (nemluvě o tom, že většina z vás by asi neměla na spuštění lokální instance tohoto vyhledávátka dostatek místa na disku a v operační paměti, nemluvě o mnoha desítek hodin trvající přípravě a naplnění databáze).